
Solving a problem
The much-anticipated Async feature is designed to solve a problem that every developer has run into when writing a GUI application, the GUI locking & freezing. Most windowing libraries avoid the need to take locks by having all of the GUI code run on a single thread, with this thread using some kind of mailbox to prevent asynchronous message arrival.
We obviously want to prevent asynchronous message arrival because, when the string of a TextBox is being updated to “fred”, we don’t want to get a message telling us to update it to “joe” while we are still in the middle of processing the change to “fred”. The key to this enforcement of linear processing is that the GUI is only going to respond to user interaction if the single GUI-owned thread is available to do processing of incoming events. If we need to do a blocking operation, such as hitting a web service, and we do it on the GUI-owned thread, then the GUI is going to feel dead, with screen updates and actions not having any effect until the blocking operation finishes.
This is unacceptable, particularly on touch controlled devices, where the feedback has to be quick if it is to be effective. Visiting some sites on my iPhone’s web browser can be painful, as I often touch to cause some kind of action, but then find that Safari is still busy processing the page. Frustratingly, this leaves me in a state where I don’t know if Safari is going to do something when it gets less busy, or whether my earlier interaction has just been ignored. WinRT is going to be designed for touch from day one, and its designers have apparently paid careful attention to existing touch Operating Systems, and learned some valuable lessons. As a result, WinRT requires all operations that are going to take more than 50 milliseconds to offer an asynchronous version (and, in lots of cases, only an asynchronous version), as a means of keeping the user experience of Metro applications slick and intuitive. The question then becomes how to make it easy for developers to use this new functionality.
New tricks
In the past we’ve been able to defer work to a later point in time by capturing the context as a closure, passing this closure to some object that is responsible for doing the wait, and then having that closure called when the code should continue running. This continuation-passing style makes the code very complicated to read, and makes it very hard to follow the control flow of the code.
Let’s take a look at an example of this using a very simplistic example. Suppose we want to read two strings from the Console, and write their total length in characters to the Console. If at any point a blank line is entered, then we don’t want to read any more data, but we still want to print the total number of characters:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
int totalCharacters = 0; string input = Console.ReadLine(); if (!string.IsNullOrEmpty(input)) { Console.WriteLine("First string: {0}", input); totalCharacters += input.Length; input = Console.ReadLine(); if (!string.IsNullOrEmpty(input)) { Console.WriteLine("Second string: {0}", input); totalCharacters += input.Length; } } Console.WriteLine(totalCharacters); |
The trouble with the above code is that it is blocking the main thread, which doesn’t matter in this case, but would if it were an operation on the GUI. The thread also sits inside Console.ReadLine, consuming the resources that a thread requires (such as 1mb of stack space), without doing any useful work. If this was some kind of (web) server application, then this would be wasteful and would inhibit scalability. Ideally, we’d really like to record the state of the program, but then pass the thread back to the runtime, only grabbing it later when we have more work to do.
Let’s say we were provided with some kind of asynchronous version of Console.ReadLine, such as a function of the following form, which takes responsibility for getting data from the console and then calling an action function with that data when it is available on some available thread:
|
1 2 3 4 5 6 7 8 9 |
static void ReadLineAndThenDo(Action<string>action) { ThreadPool.QueueUserWorkItem( delegate { string line = Console.ReadLine(); action(line); }); } |
In that situation, it would be possible for the outer function to release the thread it is running on, knowing that the action function is going to be called on a suitable thread when the result is available.
|
1 2 3 4 5 6 7 8 9 |
static void ReadLineAndThenDo(Action<string>action) { ThreadPool.QueueUserWorkItem( delegate { string line = Console.ReadLine(); action(line); }); } |
There are two different ways that you could implement the new program. You might use the continuation-passing style that we briefly mentioned earlier, using lambda expressions to capture the state of the local variables, which we can use for later parts of the computation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
static void Attempt2() { int totalCharacters= 0; ReadLineAndThenDo( input => { if (!string.IsNullOrEmpty(input)) { Console.WriteLine("First string: {0}",input); totalCharacters += input.Length; ReadLineAndThenDo( input2 => { if (!string.IsNullOrEmpty(input2)) { Console.WriteLine("Second string: {0}",input2); totalCharacters += input2.Length; } Console.WriteLine(totalCharacters); }); } }); } |
In this instance, the change has been localised to our function, but what a change it is! Every time we want to do an asynchronous call, we have had to pass in the rest of the code as a lambda expression (input => …) or (input2 => …). The indentation gets deeper and deeper, and things become very complicated if we have a loop construct of any kind in the code. The logic of the code has been obfuscated in order to fit into the programming language.
However, if we take another look at the very first version of our string reader, we can see that there are distinct sections of code, with a new section starting each time we pass control to a ReadLine. For example, we start in state one, which does the initial setup of the local variables, and we then do a ReadLine and assume we enter state two when this has finished. As we enter state two, we know that there is new input available, and we can process this until we get to the next ReadLine, which starts state three:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
/*State 0 */ inttotalCharacters = 0; string input = Console.ReadLine(); /* State 1 */ if (!string.IsNullOrEmpty(input)) { Console.WriteLine("First string: {0}",input); totalCharacters += input.Length; input = Console.ReadLine(); /* State 2 */ if (!string.IsNullOrEmpty(input)) { Console.WriteLine("Second string: {0}",input); totalCharacters += input.Length; } } /* State 3 */ Console.WriteLine(totalCharacters); |
This feels very much like what is known as a state machine in Computer Science parlance, which is the second way we can implement this program. We’ve seen such implementations used before, in the compilation of iterator blocks by the C# compiler, so there is already existing compiler technology for implementing such transformations.
We can implement the state machine using a new compiler generated class, Attempt3Machine. This will have a state variable, m_State, recording the state of the machine as one of its fields. We’ll lift the local variables of the method into the fields of the state machine (necessary because they live between the calls into our state machine), and we’ll implement the machine in a way that uses a single method to transition it from its current state to the next state. We call this method MoveNext, in the spirit of iterator blocks implementation.
Implementing a state machine
We’ll now need to change our asynchronous version of ReadLine to interact with our state machine. For the moment, the ReadLine will read a line from the Console, set this into the m_Input field which corresponds to the local variable input in the original code, and will then force the machine to make a transition:
|
1 2 3 4 5 6 7 8 9 10 |
static void ReadLineAndThenDo2(Attempt3MachinestateMachine) { ThreadPool.QueueUserWorkItem( delegate { string line = Console.ReadLine(); stateMachine.m_Input= line; stateMachine.MoveNext(); }); } |
This then leaves us with a state machine with the following implementation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
class Attempt3Machine { intm_State = 0; private int m_TotalCharacters= 0; public string m_Input; public void MoveNext() { switch (m_State) { case 0: m_State= 1; ReadLineAndThenDo2(this); return; case 1: if (!string.IsNullOrEmpty(m_Input)) { Console.WriteLine("First string: {0}",m_Input); m_TotalCharacters+= m_Input.Length; m_State= 2; ReadLineAndThenDo2(this); return; } goto case 3; case 2: if (!string.IsNullOrEmpty(m_Input)) { Console.WriteLine("Second string: {0}",m_Input); m_TotalCharacters+= m_Input.Length; } goto case 3; case 3: Console.WriteLine(m_TotalCharacters); return; } } } |
And with a method that uses this of the form:
|
1 2 3 4 |
static void Attempt3() { new Attempt3Machine().MoveNext(); } |
Results
So where has this got us? Well, the translation between the code above and something that started out like the following is fairly mechanical:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
int totalCharacters = 0; string input = await Console.ReadLine(); if (!string.IsNullOrEmpty(input)) { Console.WriteLine("First string: {0}", input); totalCharacters += input.Length; input = await Console.ReadLine(); if (!string.IsNullOrEmpty(input)) { Console.WriteLine("Second string: {0}", input); totalCharacters += input.Length; } } Console.WriteLine(totalCharacters); |
The position of the Await expressions tells us where we need to have new states for the state machine, and we simply need to push the code in-between into the relevant state transition blocks.
By using the Await in the above code, we have kept the code in a state where it is easy to follow the control flow, even though the method stops running at the point where the await is called.
Tidying up with Tasks
There are, of course, several loose ends to tidy up. First, it looks easy in the above code to split the code into the transitions on a line by line basis, but in reality you can put multiple Await expressions in a single statement:
|
1 |
int x = await f() + await g(); |
This means we may need a new field location to store the result of the first Await while we are waiting for the second Await to complete. We could use several locations, or just have a single location that stores the intermediate value typed as an object, and then cast as necessary when wanting to use this value. The current semantics of await only allow a single outstanding call at any time, so we need to wait for f() to finish before g() is launched.
If we have an Async function, then the caller needs to have something that they can use to get the value when it is finally calculated. .NET 4 included the rather brilliant Task<> abstraction, which reflects a computation that may still be running. A Task<int> object, for example, represents a calculation that may eventually return an integer. Using its Result property, a client can fish out the result value, blocking until it is available, and find out details of any exceptions that were thrown. Tasks support a number of very powerful operators, such as a ContinueWith (which allows you to schedule the execution of one task when some other task completes), and a means of waiting for one or many tasks to finish. Tasks also support a model of synchronous cancellation, with the user function being expected to regularly check for a demand for cancellation, and throwing an exception if this is required. As a result, any method that uses await must either return void or Task<…>.
Some Considerations
Threading always adds complication to any design, and our current example doesn’t really have a good threading model. Some operations need to be called on certain threads, so our code would really need to transition back onto one of these threads before it is called, probably by using the Post operation of the synchronization context that was active when we launched the asynchronous call. .NET also has a notion of an execution context which may need to flow across to any worker threads that are launched. We may need to capture these values when we launch a call, and then get back to the correct state before we restart in the next transition.
Exceptions also need to handled and stored away in the Task object associated with the current method, so that callers can later get the correct details of what went wrong. If the method finishes successfully, we’re also going to need to store the result away in the task, or at least mark the task as finished if there is no return value. This will allow callers to wait on our method finishing.
There are also several missing pieces in the story of the communication between the state machine (when it fires off the asynchronous work) and the object that is going to do the work. The example above hacked this, by having the asynchronous method we were calling (DoReadLineAndThenDo) know lots of detail about the caller, such as the field in which to write the return value. This code is obviously too specific, and is purely for demonstration purposes. We get around this by adding indirection, having the asynchronous ReadLine return a Task, and then hook an OnCompletion action to the returned task which causes the state machine to move to the next state.
Also, the action may complete really quickly, or might even have finished already. In that case it is a real waste of effort to go through the mechanism of returning from MoveNext and then having a MoveNext transition called by an external party. We could have simply jumped to the new state in the MoveNext implementation itself, without going through the capture state and then restore process. This is handled, as we’ll see in my next blog post, by having an Awaiter pattern which includes the asynchronous object, providing a property called IsCompleted which can be used to allow the MoveNext to instantly transition to the next state. The result will be fetched using GetResult.
Decompiling Async Code
Asynchronous code is clearly incredibly useful, and remarkably cunning in its implementation. In the .NET Reflector team where I work, it has taken a lot of effort to make sure .NET Reflector can accurately decompile asynchronous code so that you can start investigating C#5 code right away. Hopefully you will then be able to see how quickly Async code can start to become convoluted, and how backtracking the various calls and state transitions in a real application poses a challenge.
Async is remarkably cunning, and can become tortuously tricky to follow when applied in a real application, which naturally makes any decompilation a bit of a challenge.
We’ve implemented support for the decompilation of async inside .NET Reflector, so all the code you’ll see later on in this article will be generated by Reflector, both before and after the translation phase that deals with the async state machines.
You need to be aware that there are several implementations of Async in the code that we’ll see, because there are different implementations of Async in the code that you find in the .NET 4.5 framework libraries compared with code that is compiled using the Dev11 C# 5 compiler. For our Reflector work we are currently working on the former, mainly because the fundamental part of the work (the processing of the state machine) is the same in both cases, and the framework libraries contain hundreds of potential test cases.
Real code
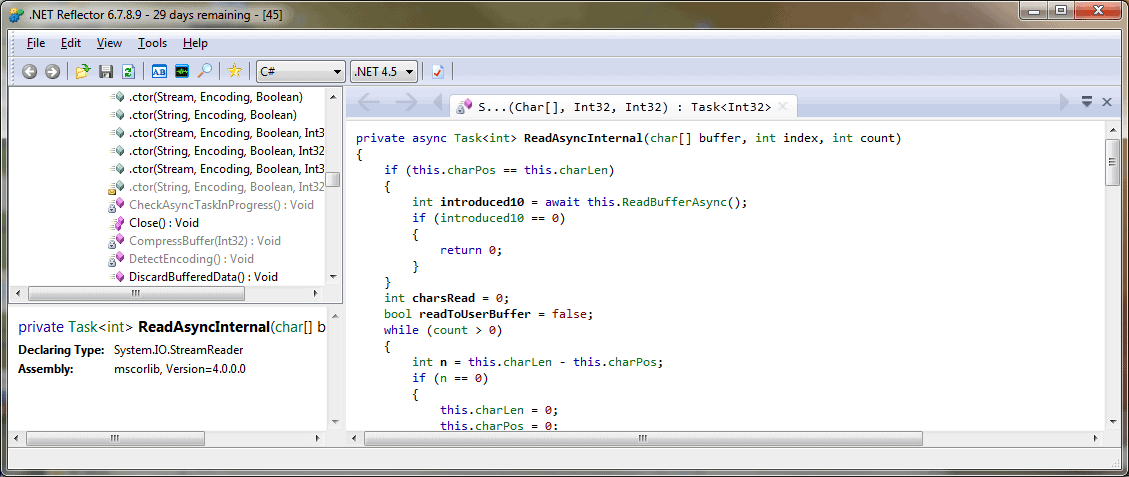
If you look at the ReadAsyncInternal method in the .NET 4.5 version of mscorlib, you’ll see that it has the following code:
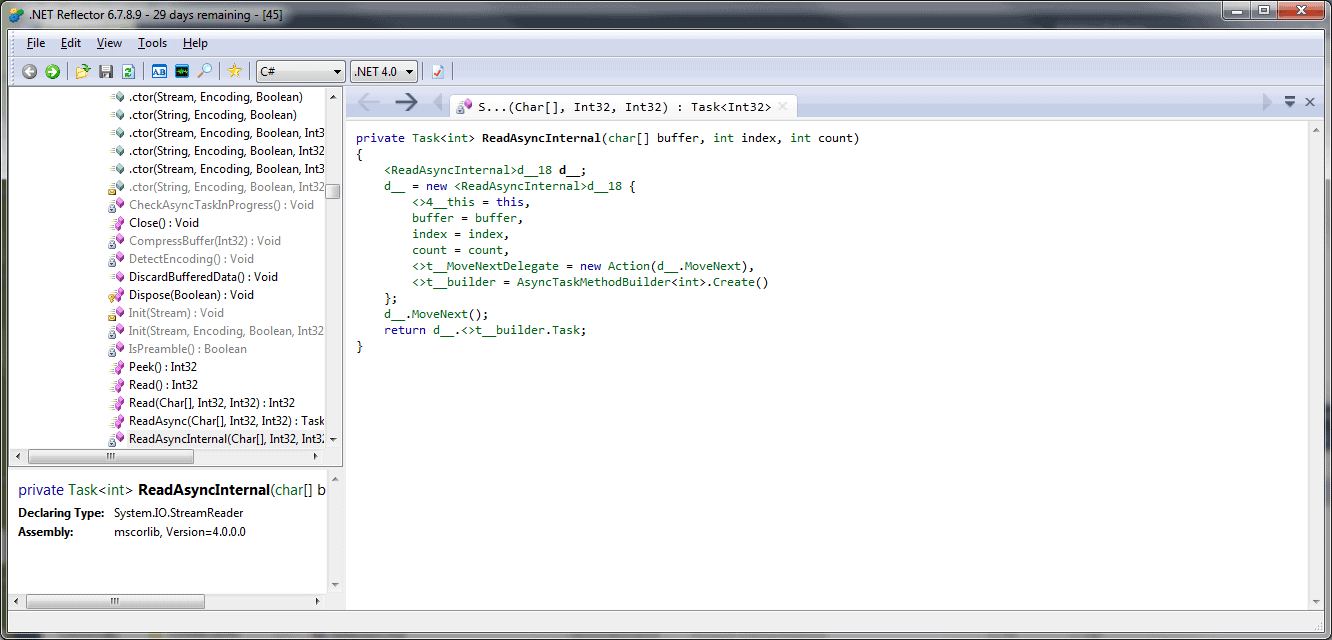
Click for an enlarged version
Remember, from our earlier example of the simple string-reader program, the compiler generates a class which implements the state machine, setting the various fields corresponding to the arguments and the local variables, which get lifted into this class. The <>t__builder is an instance of AsyncTaskMethodBuilder, which is used to do the plumbing between the client and the implementation of the async method, and we’ll see it used in the MoveNext method.
The compiler-generated class has the following form:
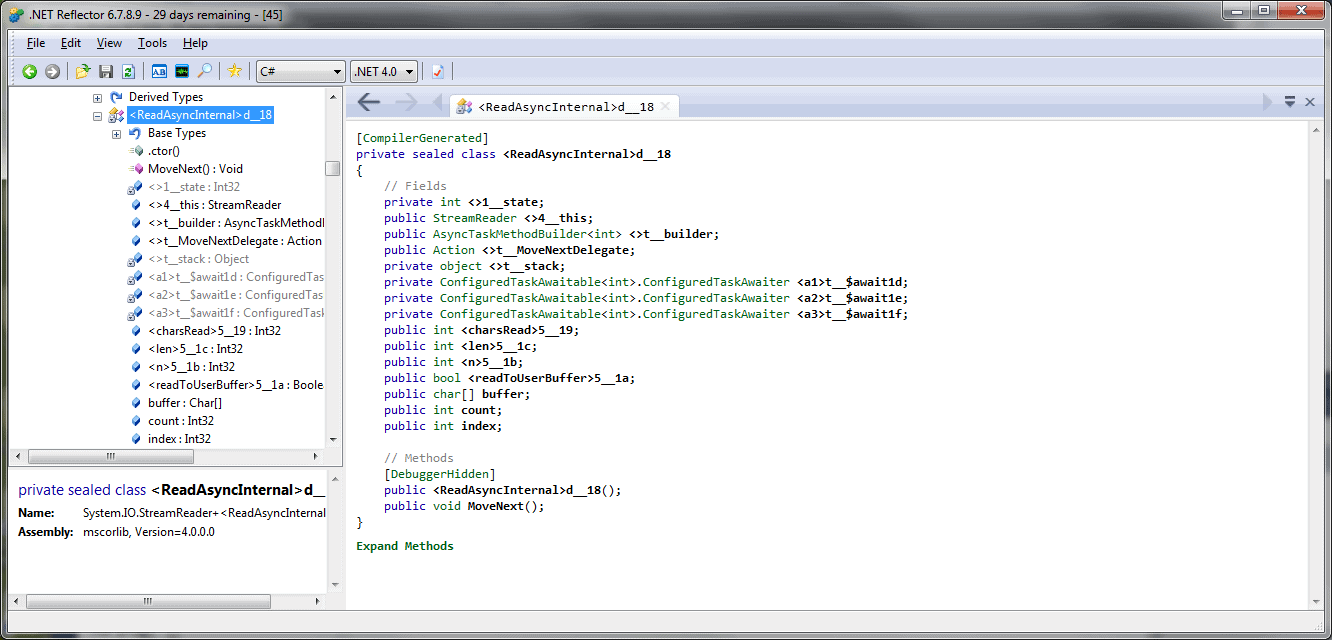
Click for an enlarged version
Notice the state value field <>1__state, and the field <>4__ this which allows access back to the original instance of StreamReader which constructed this instance of the state machine.
For us, the really interesting part is the code in the MoveNext method:
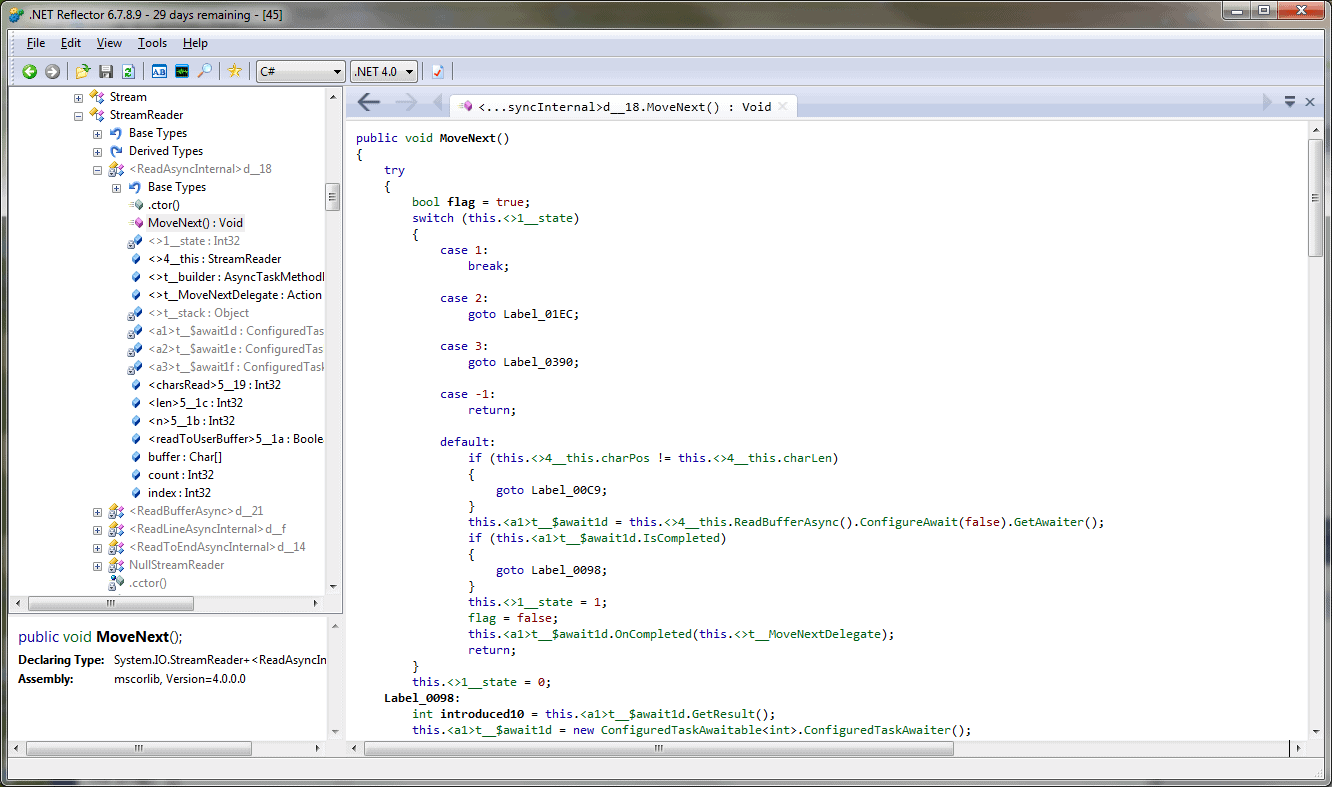
Click for an enlarged version
The outer Try has a body that ends with the code:
|
1 2 3 4 5 6 7 8 9 |
this.<>l_state = -1; this.<>t_builder. SetResult(this. <charsRead>5_19); } catch (Exception exception) { this.<>l_state = -1; this.<>t_builder. SetException (exception); } } |
Let’s take a quick walk through the implications of this.
Stepping through the code
In the exception case we set the state to -1, which is a state that causes the MoveNext to return instantly while remaining in that state. In the success case, we store the function result value using the SetResult, which ends up setting the value into the Task associated with this invocation of the method. Likewise, the SetException sets the Exception property of the Task object, taking care to specially handle the OperationCanceledException, which is used by the Task library to communicate that a synchronous cancellation request was successfully honoured. After this, anyone waiting on the Task will be notified that they can continue running via the usual implementation in the Task class.
It’s fairly easy to follow the code around while keeping an eye on the state transitions, but the most interesting thing that happens occurs when we call out to some asynchronous method, such as in the following code fragment:

Our method is calling into the ReadAsync method:

This returns a Task which will eventually contain a count of the number of bytes read, potentially also modifying the arrays that were passed in as arguments.
We now get a slight complication. In order to control whether the synchronization context and other information needs to be preserved, the Task is passed through the .ConfigureAwait method before its GetAwaiter is called. This result of the call to GetAwaiter() supports the Await pattern; it is expected to have certain methods implemented on it, much like an Enumerable is expected to have a GetEnumerator method. Let’s take a look at how this process can proceed.
First we have the quick path: when IsCompleted returns true to say that the result is already available, we can jump straight to label 03AD. Otherwise, things get a little more complicated: we need to save any state we’re going to need later into a field in the current object, set up the OnCompleted action of the task so that the MoveNext method is going to be called again, set the state field to the next state, and return. At some point, assuming no exceptions, we’ll be called back, the state value will ensure that we reach label 0390, where we can get back the values that we saved away, and then continue to the same place that we’d have gone in the fast path.
At that location, we’ll get the result of the asynchronous operation using GetResult and carry on as if we had been running all the time. Notice that all of the thread transitions (if any are required) are hidden away inside the object that is returned by GetAwaiter, which is responsible for getting us to the right place before it calls the delegate that was passed into OnCompleted.
Not one compiler, but two
As I mentioned earlier, part of the challenge in understand all this comes as a result that we’re targeting at least two, subtly different, compilers. Thus far we’ve been looking at the results of the compiler used to generate the .NET 4.5 framework libraries, so how does this all change if you use the compiler that ships with the latest Dev11 beta?
First there is now an interface, IAsyncStateMachine, that constrains the interface between the state machine and the code that uses it:

This is implemented by the compiler generated type which is now a struct instead of a class:
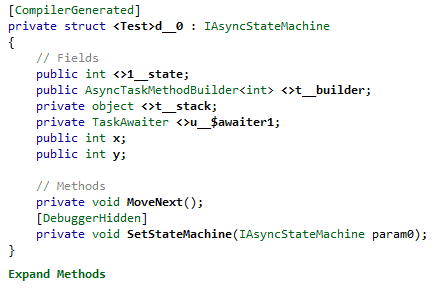
The initialization code also looks a little different:
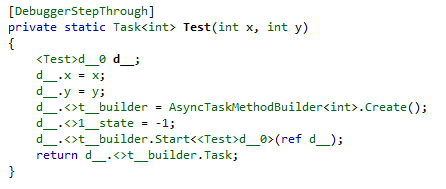
The body of the MoveNext is still surrounded by a Try Catch block as before, though the code to fire off an asynchronous call now has slightly fewer lines to it, using the builder to do more of the work. As before, if the operation doesn’t instantly complete, the state is set, and we set up a notification from the called method so that we’ll be brought back after the operation completes. In order to do this, we need to pass in the awaiter and the state machine object by using the ref modifier on the call:
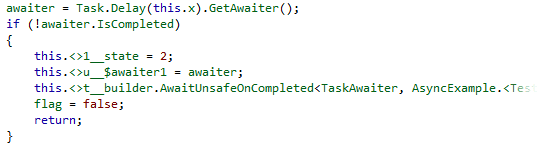
The idea is the same as the previous implementation, though the mechanics of capturing the relevant synchronization and execution contexts is a little different. If you want to see what I mean, take a look at the code in the AsyncTaskmethodBuilder class in System.Runtime.CompilerServices in the .NET 4.5 version of mscorlib.dll.
By looking out for the pattern of Async code, Reflector can fold code back into the form using async/await. So, for example, the above example will be displayed as:
Click for an enlarged version
Summary
Async is implemented using a compiler transform to implement code as a state machine, though this requires a few support classes in the runtime library, and that a set of methods need to be implemented on types that support asynchronous calls following the Await pattern. No changes are required to the CLR, though some support has been added inside mscorlib, and extra methods have been added to the Task<…> type to support the calls of the Awaiter pattern.
From the point of view of a tool like Reflector, having the compiler do a transform, rather than implementing the feature as something built into the CLR, unsurprisingly makes life harder for a decompiler. There’s no metadata to say some set of IL instructions are here as the result of the translation of an await, so instead the decompiler needs to look for the pattern of calls that is generated by the C# compiler. This is exactly the kind of thing that is already done to recognise lambda expressions and iterator blocks, which are also implemented by the compiler rather than the CLR. Given that, as we saw in the previous post, a basic state machine can be lashed together using lambda expressions and iterator blocks, the similarities in the both the implementation and our solution are no surprise.
Async allows you to fairly transparently run non-blocking code on a single thread, and user code looks very much like it would for a straightforward blocking implementation. In fact, you can almost write it that way first, and then change it into non-blocking code by just changing the method’s return type to Type<…>, marking it with async, and then using await and asynchronous versions of methods that you call.
Naturally, it isn’t quite that simple in practice. For example, having a function return too early might not interact well with constructs such as locks and exception handlers, and potentially offers the chance of re-entrancy in cases that were previously safe. Nevertheless, async is not as opaque as perhaps it first seems, and you could learn a huge amount by using .NET Reflector to start investigating C#5 as soon as possible.
![]() Interested in how your async code performs? The Beta release of ANTS Performance Profiler 8 adds a new async profiling mode to help you understand where applications spend their time while doing async work. Try the Beta.
Interested in how your async code performs? The Beta release of ANTS Performance Profiler 8 adds a new async profiling mode to help you understand where applications spend their time while doing async work. Try the Beta.
Load comments